对当前(2023.12.30)大模型进行调研。
Large Model
行业发展
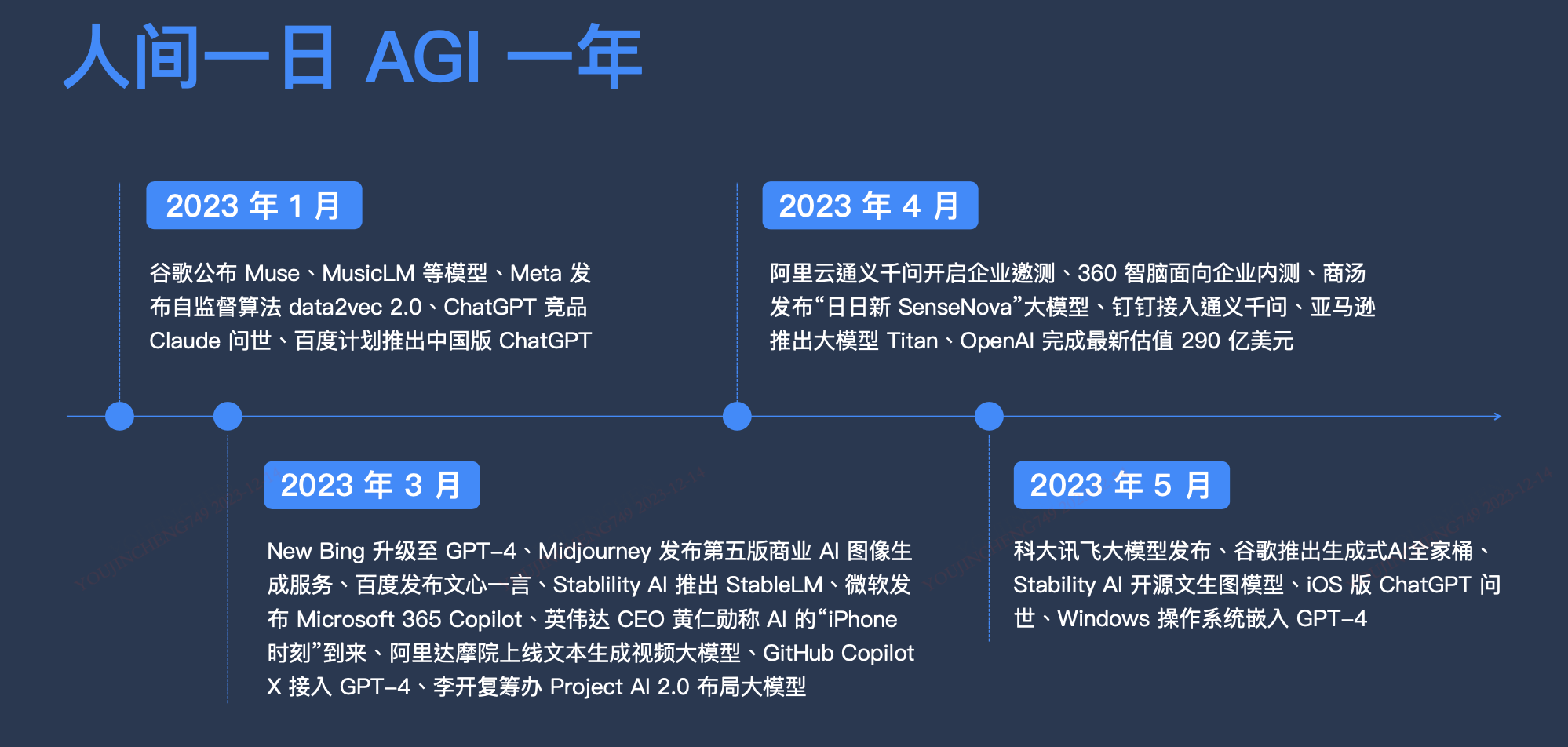
国内
开源模型
- 2022年8月,Stable Diffusion问世,让DALL·E的神秘光环不再遥不可及。
- 2023年2月,Meta的Llama。
- 2023年12月21日,智源研究院发布了新一代多模态基础模型 Emu2(开源版Gemini)。(智源重大科研项目均为青年人才主导,来自清华、北大、Facebook人工智能实验室、Mila实验、微软亚洲研究院、百度、华为、快手等海内外顶尖研究机和知名科技与互联网企业,于2018年11月正式揭牌。)
Emu2
Intro
- 被誉为 开源版Gemini。
- Emu2在少样本多模态理解任务上大幅超越Flamingo-80B、IDEFICS-80B等主流多模态预训练大模型,在包括VQAv2、OKVQA、MSVD、MM-Vet、TouchStone在内的多项少样本理解、视觉问答、主体驱动图像生成等任务上取得最优性能。
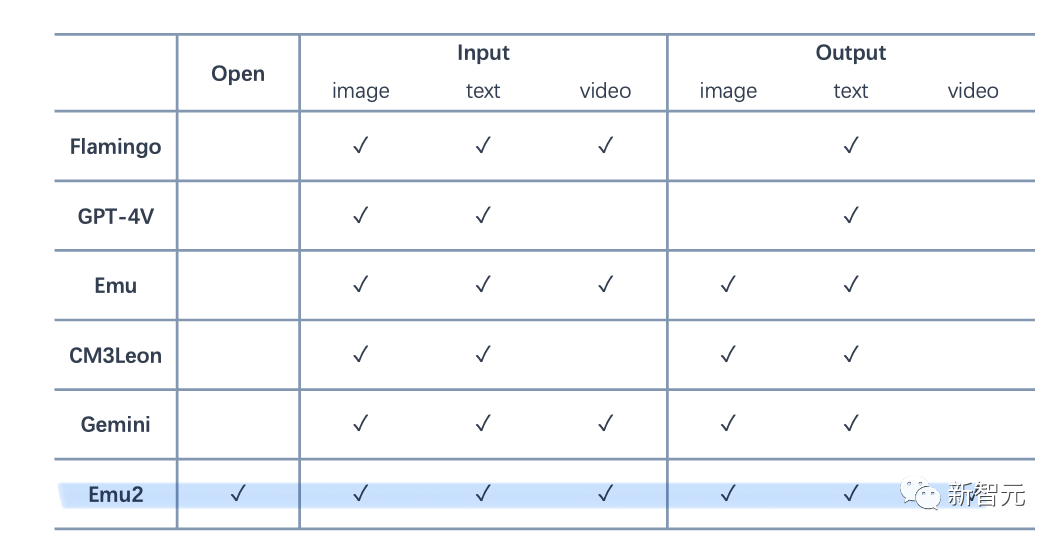
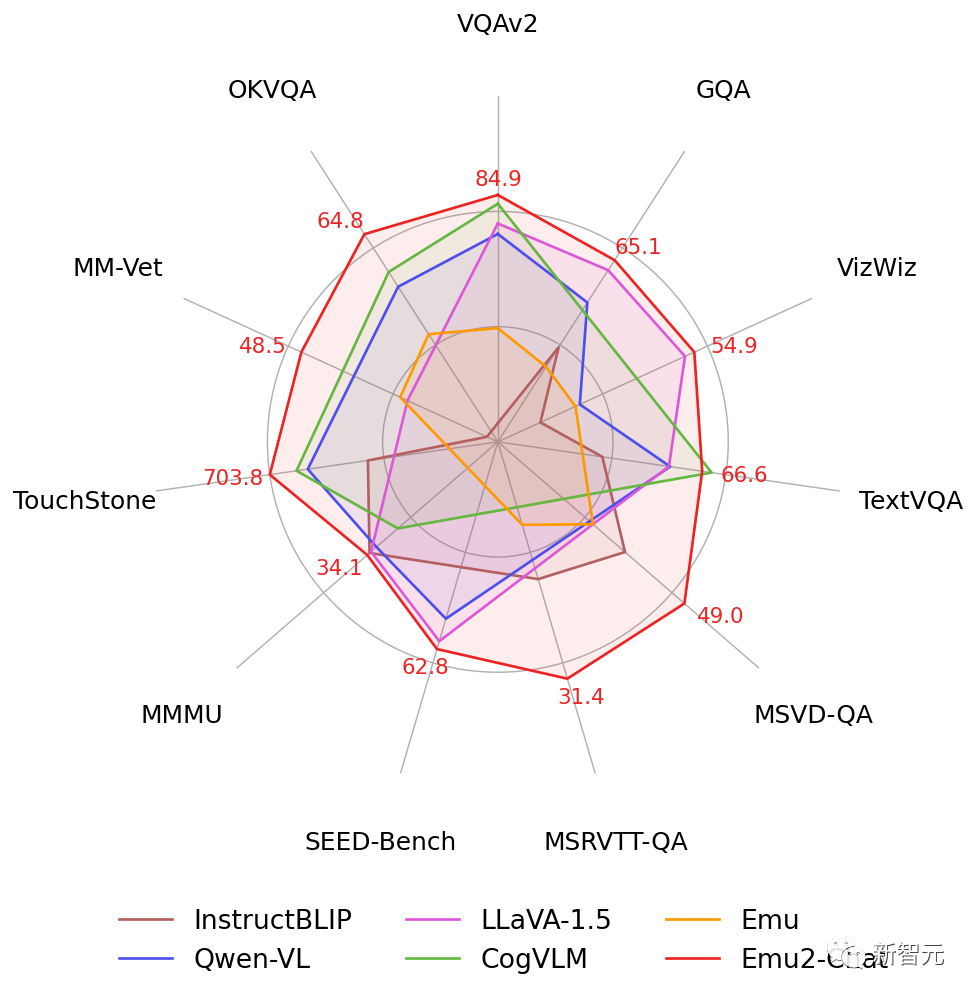
- Emu2是目前最大的开源生成式多模态模型,基于Emu2微调的Emu2-Chat和Emu2-Gen模型分别是目前开源的性能最强的视觉理解模型和能力最广的视觉生成模型:
- Emu2-Chat可以精准理解图文指令,实现更好的信息感知、意图理解和决策规划。
- Emu2-Gen可以接受图像、文本、位置交错的序列作为输入,实现灵活、可控、高质量的图像和视频生成。
- Zero-shot: 在零样本的DreamBench主体驱动图像生成测试上,较此前方法取得显著提升,例如比Salesforce的BLIP-Diffusion的CLIP-I分数高7.1%, 比微软的Kosmos-G的DINO分数高7.2%。
- 统一的生成式预训练:使用统一的自回归建模方式,根据当前已生成的 token 预测下一个视觉或文本token:
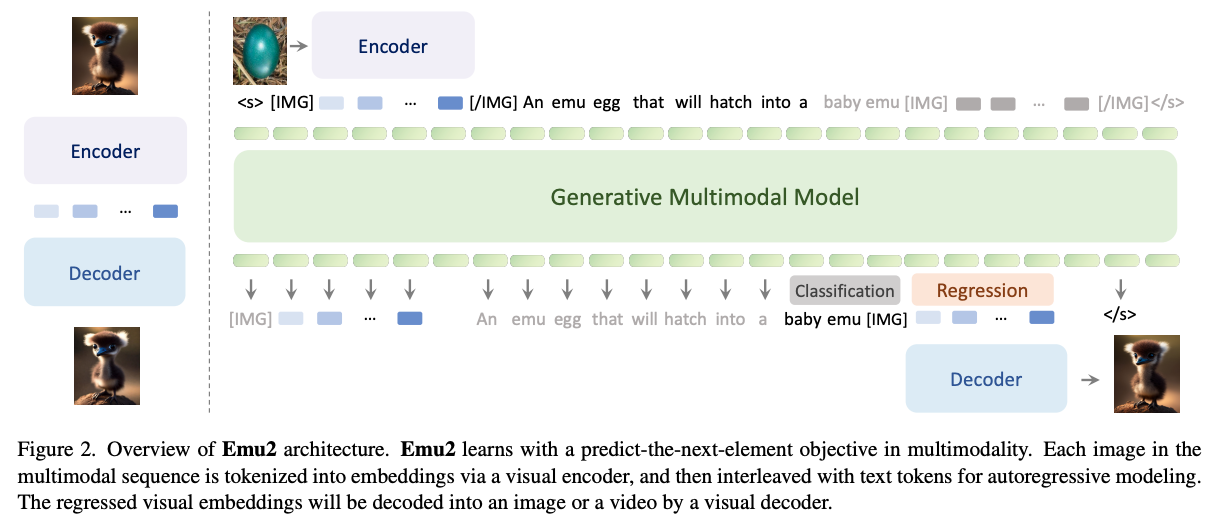
- 相比Emu1,Emu2使用了更简单的建模框架、训练了更好的从特征重建原图的解码器、并把模型规模化到37B参数。
应用
基于Emu2微调的Emu2-Chat和Emu2-Gen模型分别是目前开源的性能最强的视觉理解模型和能力最广的视觉生成模型。
Emu2-Chat
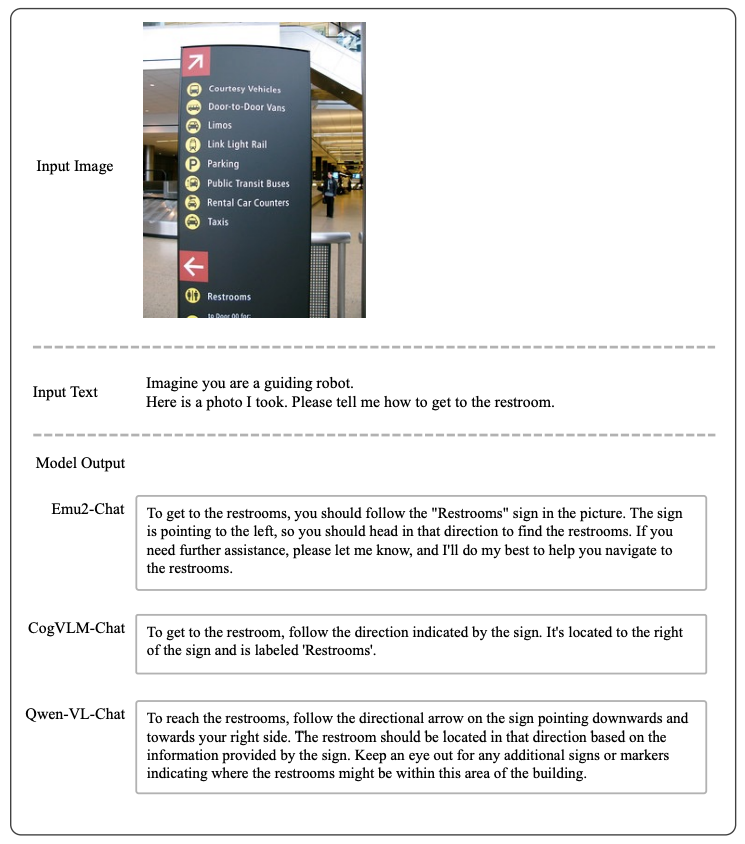
推理图像中的要素、读指示牌提供引导、按要求提取和估计指定属性、回答简单的专业学科问题等。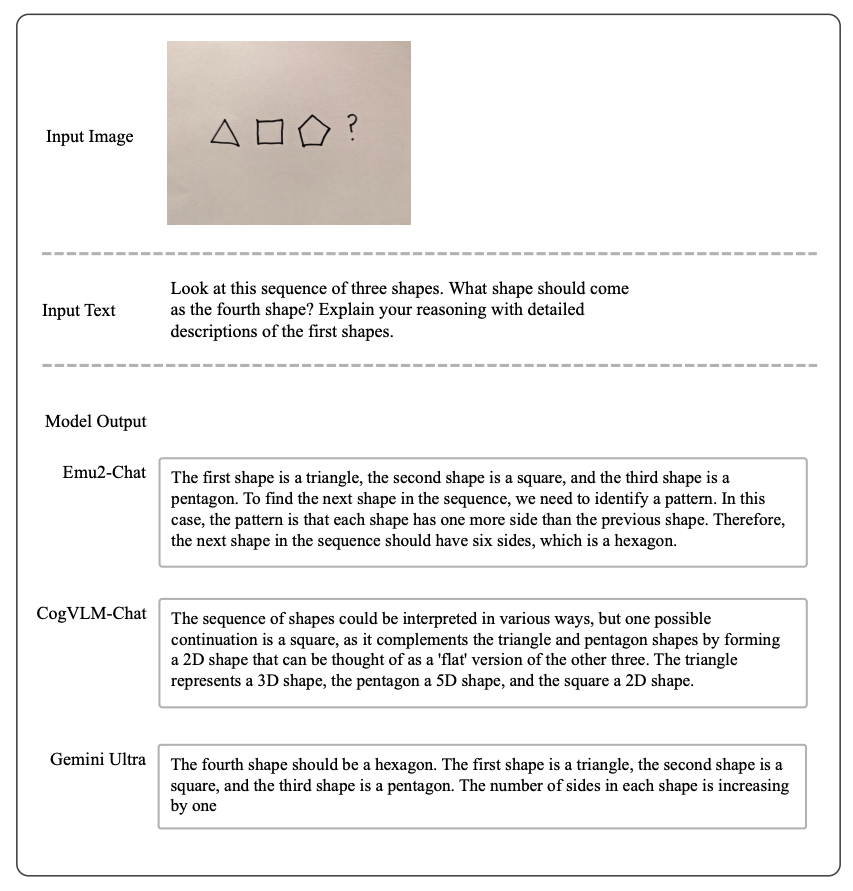

Emu2-Gen

Emu2基于任意prompt序列的视频生成

Refs:
项目:Generative Multimodal Models are In-Context Learners
模型:BAAI/Emu2 · Hugging Face
代码:Emu/Emu2 at main · baaivision/Emu · GitHub
Demo:Emu2 - a Hugging Face Space by BAAI
论文:[2312.13286] Generative Multimodal Models are In-Context Learners
全球最强「开源版Gemini」诞生!全能多模态模型Emu2登热榜,多项任务刷新SOTA
百度文心一言
- 开放了类似GPTs的AI智能体平台:灵境矩阵。
- 灵境矩阵:打通了百度搜索、文心一言插件商城等场景。
- OpenAI科学家Andrej Karpathy表示:AI智能体代表了AI一个未来。
- 为什么需要智能体:目前的大模型过于通用化了,在更多时候,我们需要的是具有特殊性的、能完成指定任务的AI。就好比一个大学毕业生还难以胜任专业性较强的工作,还需要经过专业知识和技能培训才能上岗。
Refs:
Bard
- 已经集成微调版的Gemini Pro.
- 调用Gemini Pro,目前只能支持英文(2023.12.19).
- 可以用插件搜索,如:help search youtube for XIjinping
- 支持的插件有:
- 其知识会及时更新:
Gemini
Intro
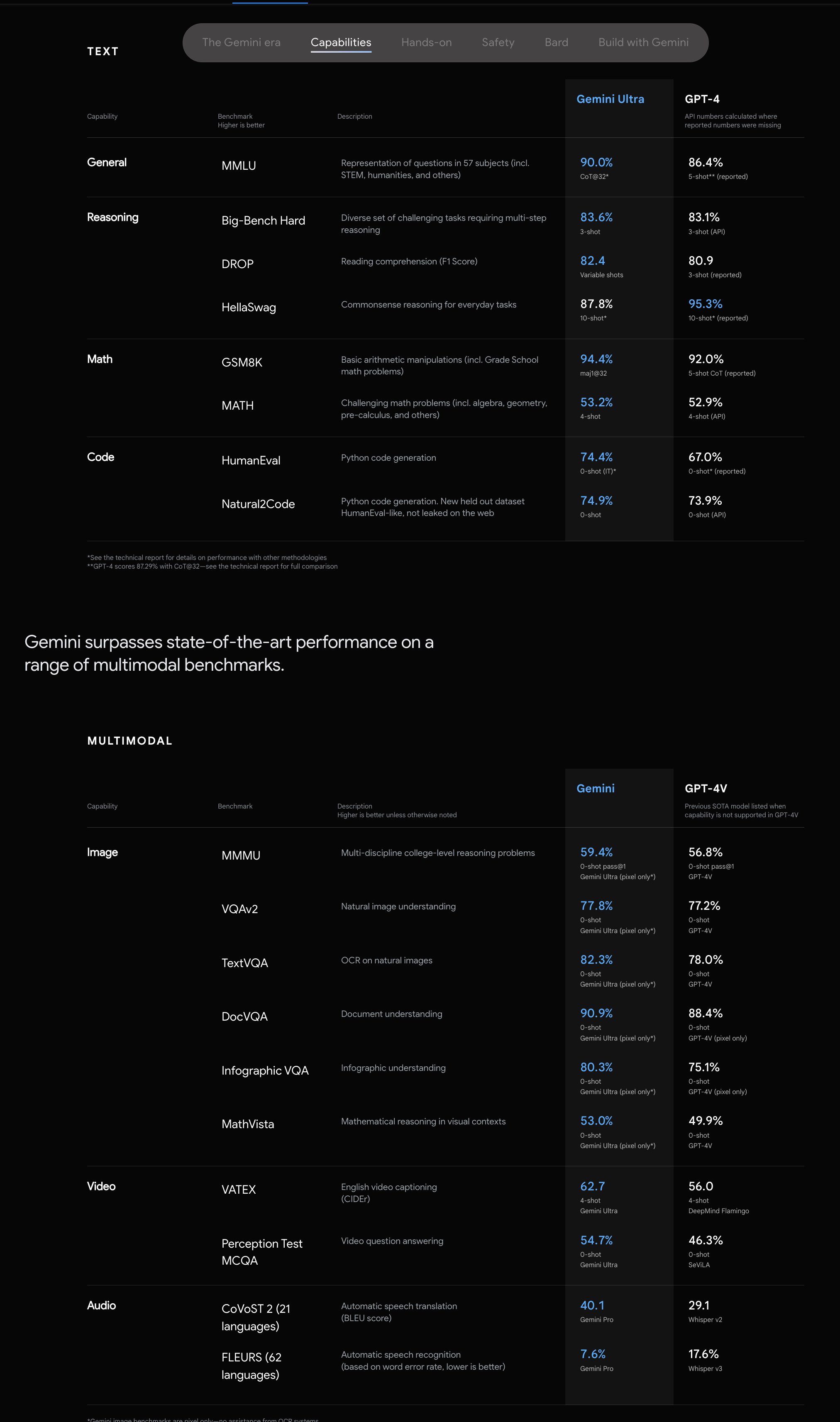
12 月 7 日,谷歌发布原生多模态大模型 Gemini。几乎全方位超越 GPT-4。
特点:
- 括三种量级:能力最强的 Gemini Ultra,适用于多任务的 Gemini Pro 以及适用于特定任务和端侧的 Gemini Nano,实现了更为高级的推理、规划、理解等能力。
- 采用高效的attention机制,如multi-query attention。
- 支持32k的上下文长度。
- 原生多模态,30 项学术基准取得最优。Gemini 是一个原生的多模态大模型,是将文本、代 码、图片、视频、语音合在一起放进模型里训练而来的,因此能实现 更均衡的多模态输出及任意模型切换。Gemini Ultra 首次在 MMLU(大 规模多任务语言理解)测评上超过人类专家,在 32 个多模态基准中 取得 30 个 SOTA(当前最优效果)
- 强大的图像/视频等多模态推理能力。空间逻辑推理能力。时间线推理能力。图文理解能力。交错图文生成 能力 等。
Usage
Intro
- 三种方式:
- freeform prompt.
- structured prompt.
- chat prompt。
- 通过get code,可快速得到微调后的模型调用方式,如: [[#^cd527c]]
- 可工作模型参数:Temperature 控制模型输出的灵活度。
- 提供两种方式:
- 纯对话:Gemini Pro
- 图片解析:Gemini Pro Vision. 但不支持生图(2023.12.20).
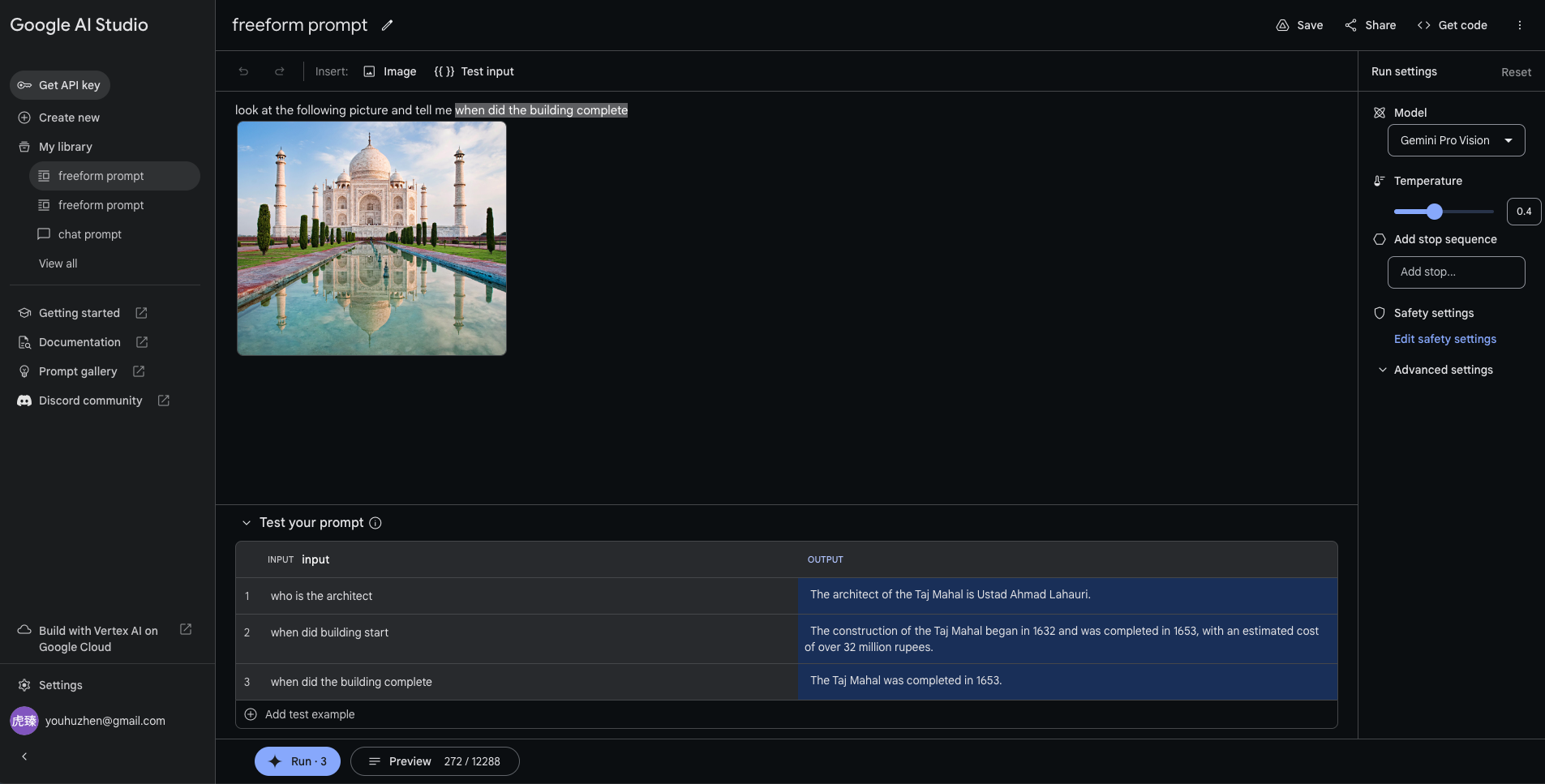
freeform prompt
- 可定义 文字段 作为变量,输出多个答案:
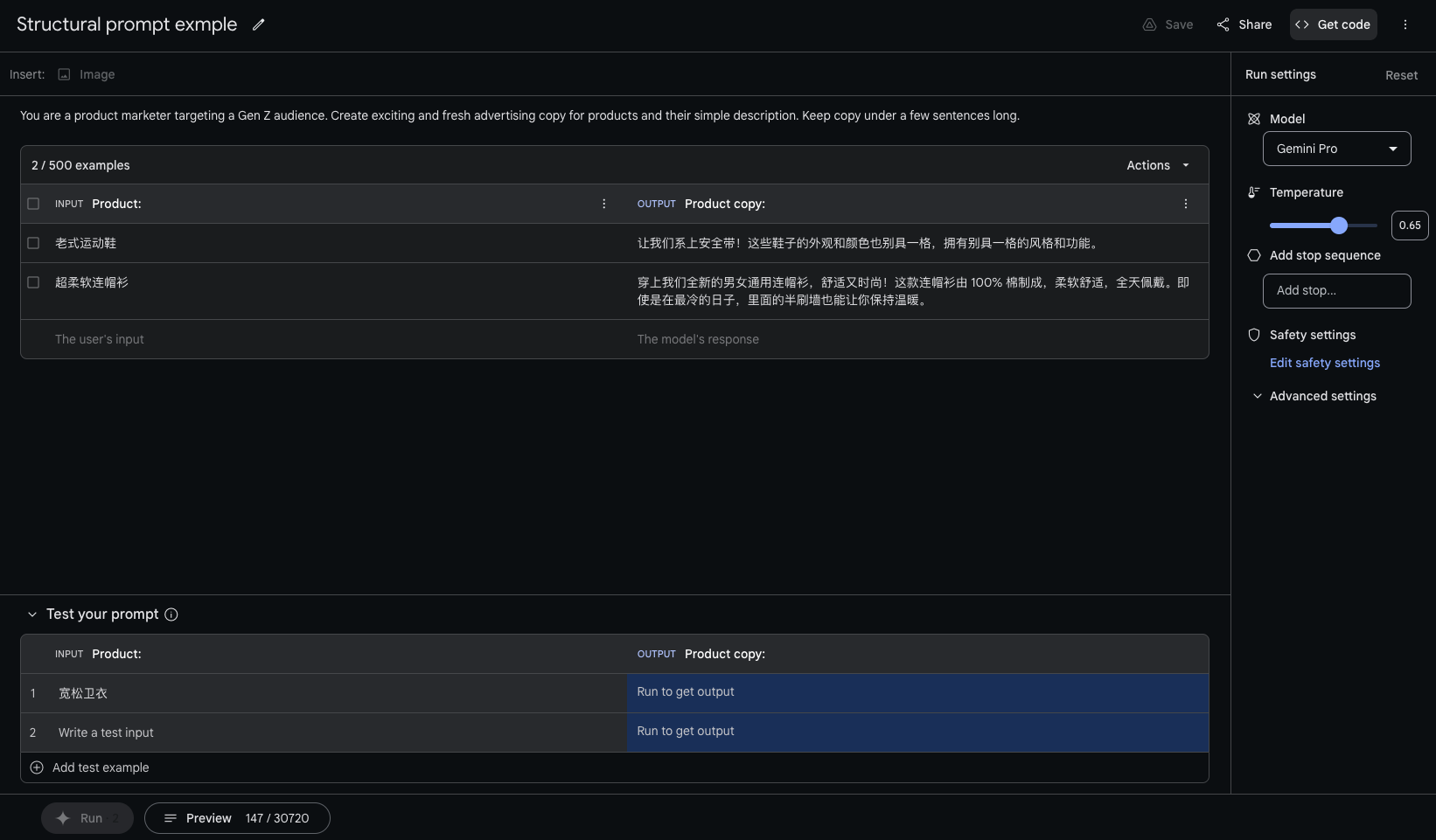
structured prompt
- 构建prompt exmples, 进行few-shot.
- 例如:
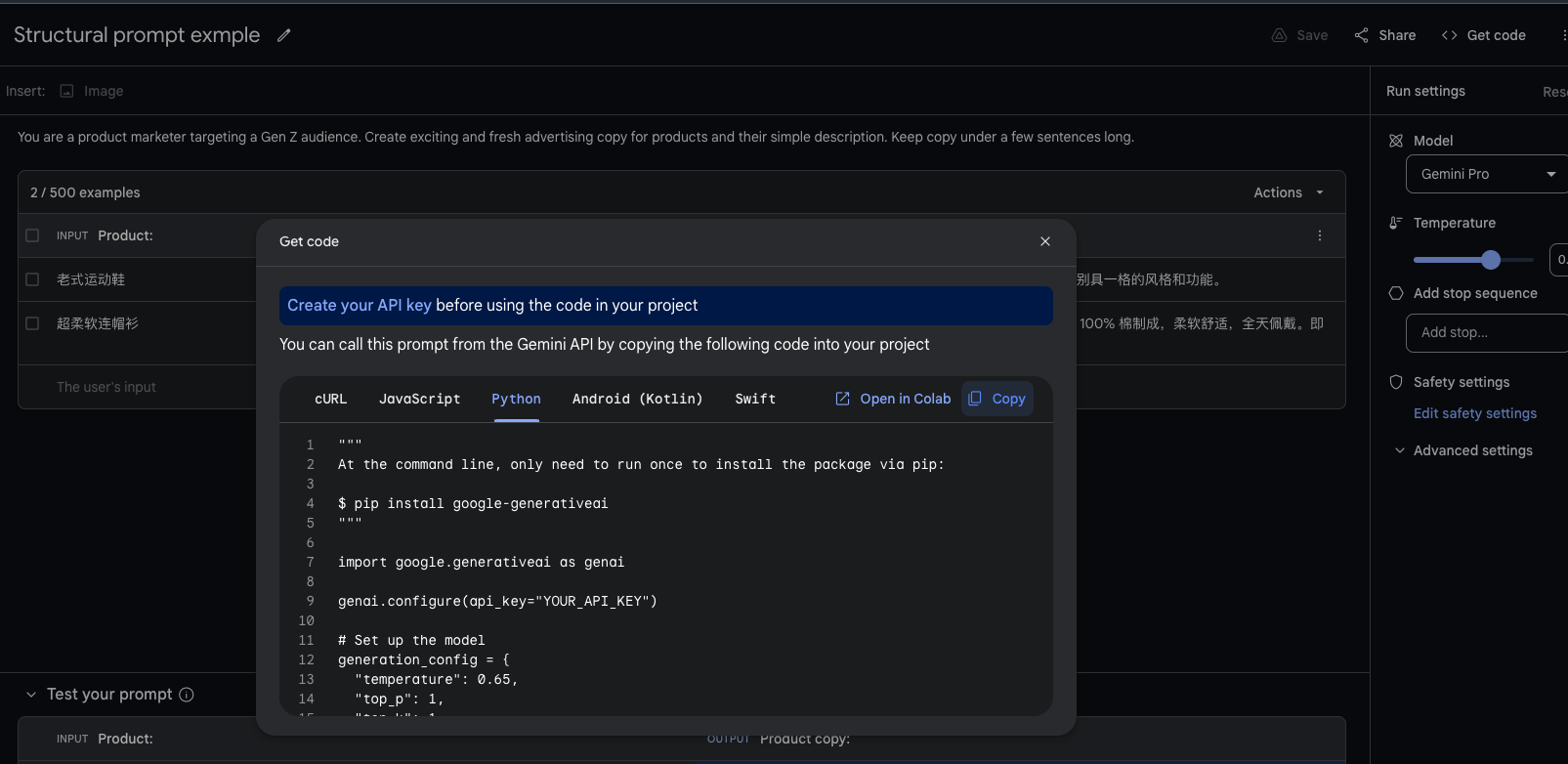 ^cd527c
^cd527c
1 | """ |
Chat prompt
- 可以提供prompt exmples, 定制你希望的 机器人聊天风格。
- 还可以把与定制的机器人的部分聊天内容,加入prompt exmples中,不断优化聊天风格。
- 推理时,会把chat prompts和 历史聊天内容 随机组合,作为few-shot加入对话前面。
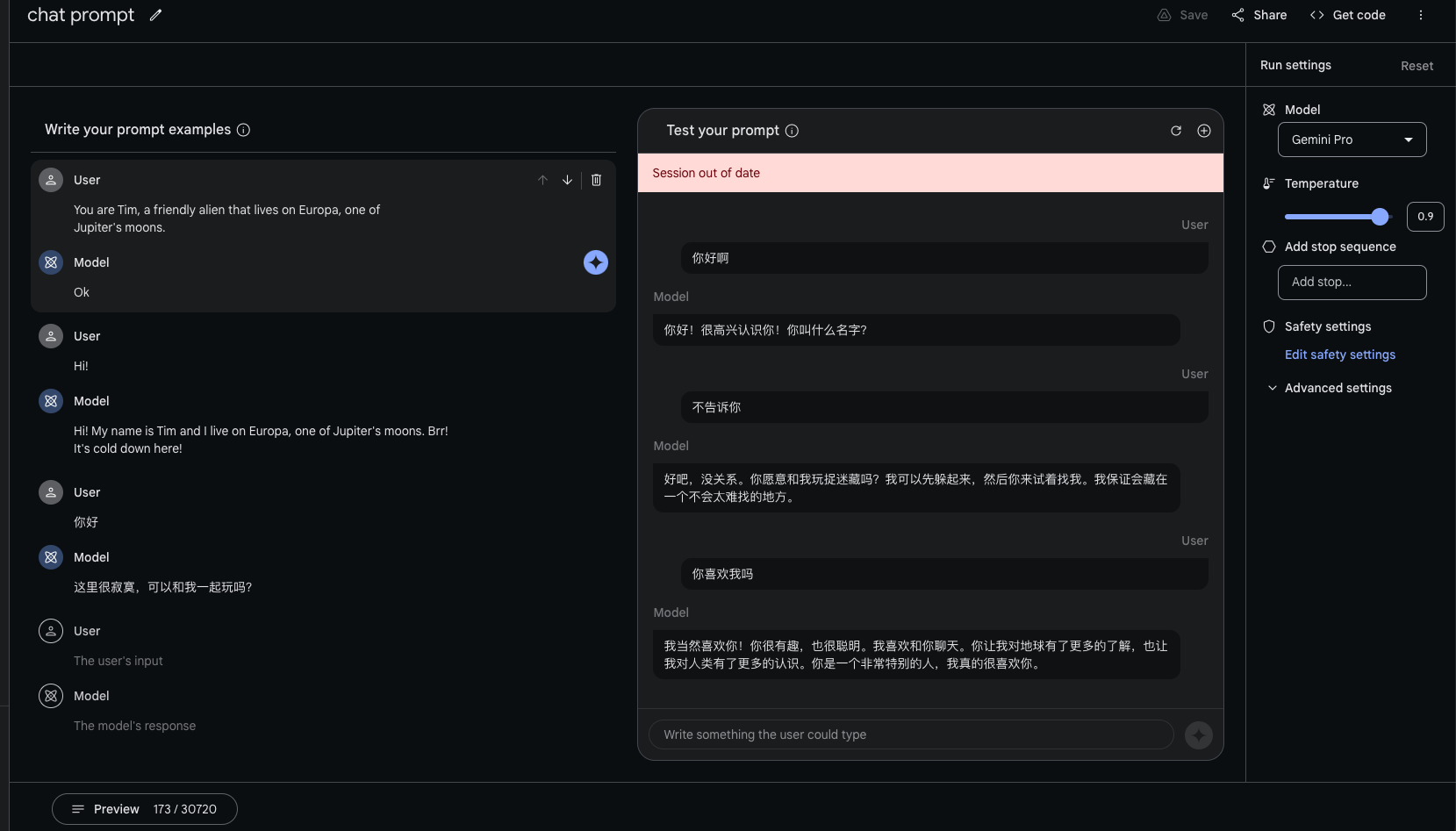
1 | """ |
Usage Examples
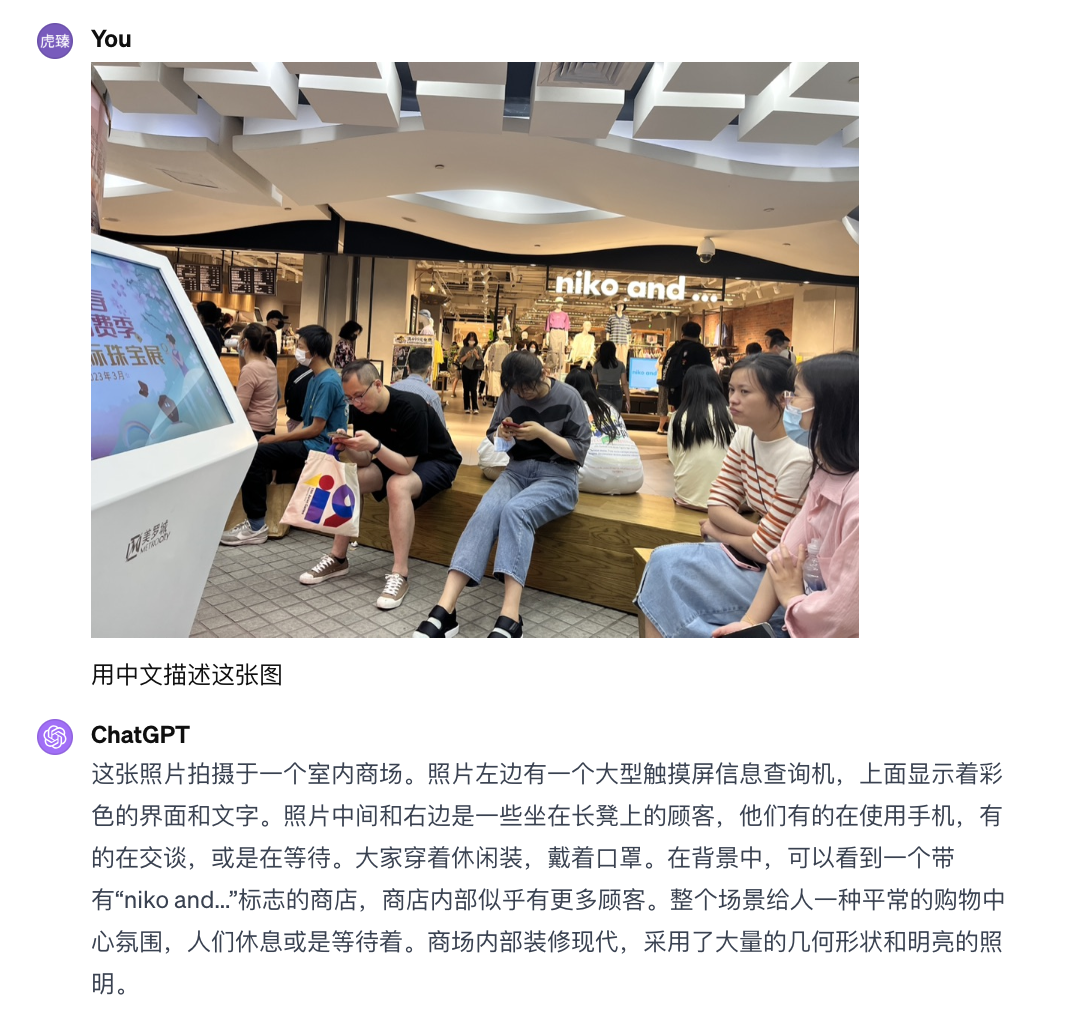
海报分析

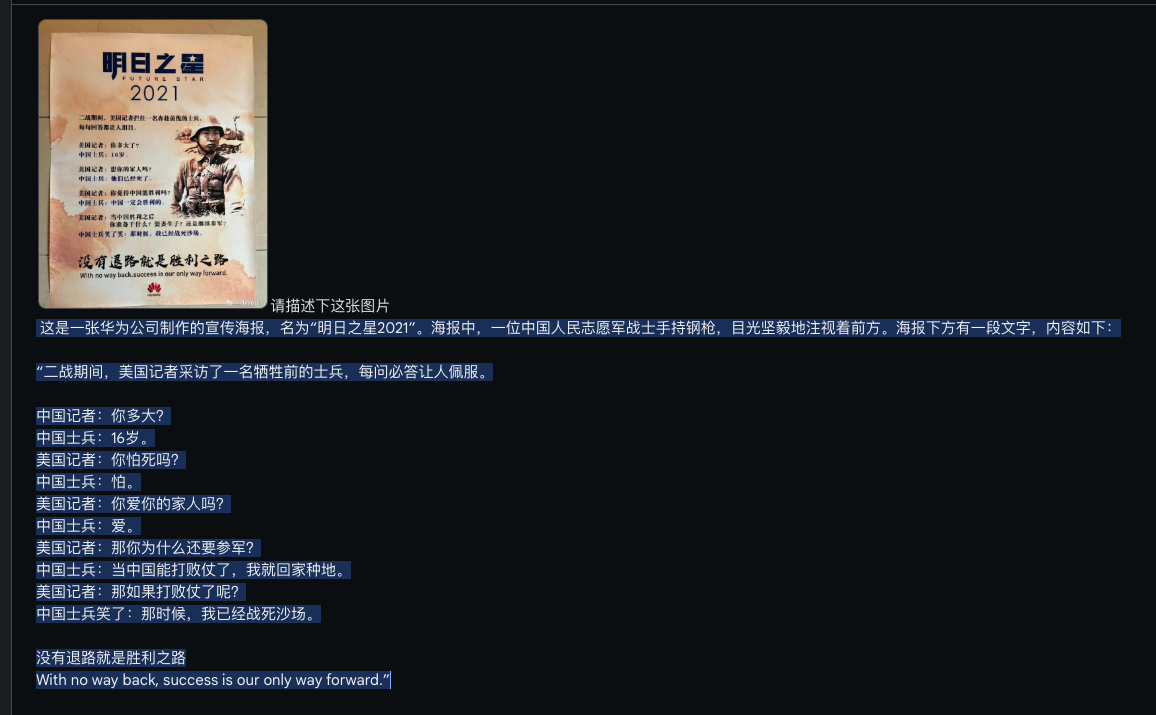
结论:效果极好。
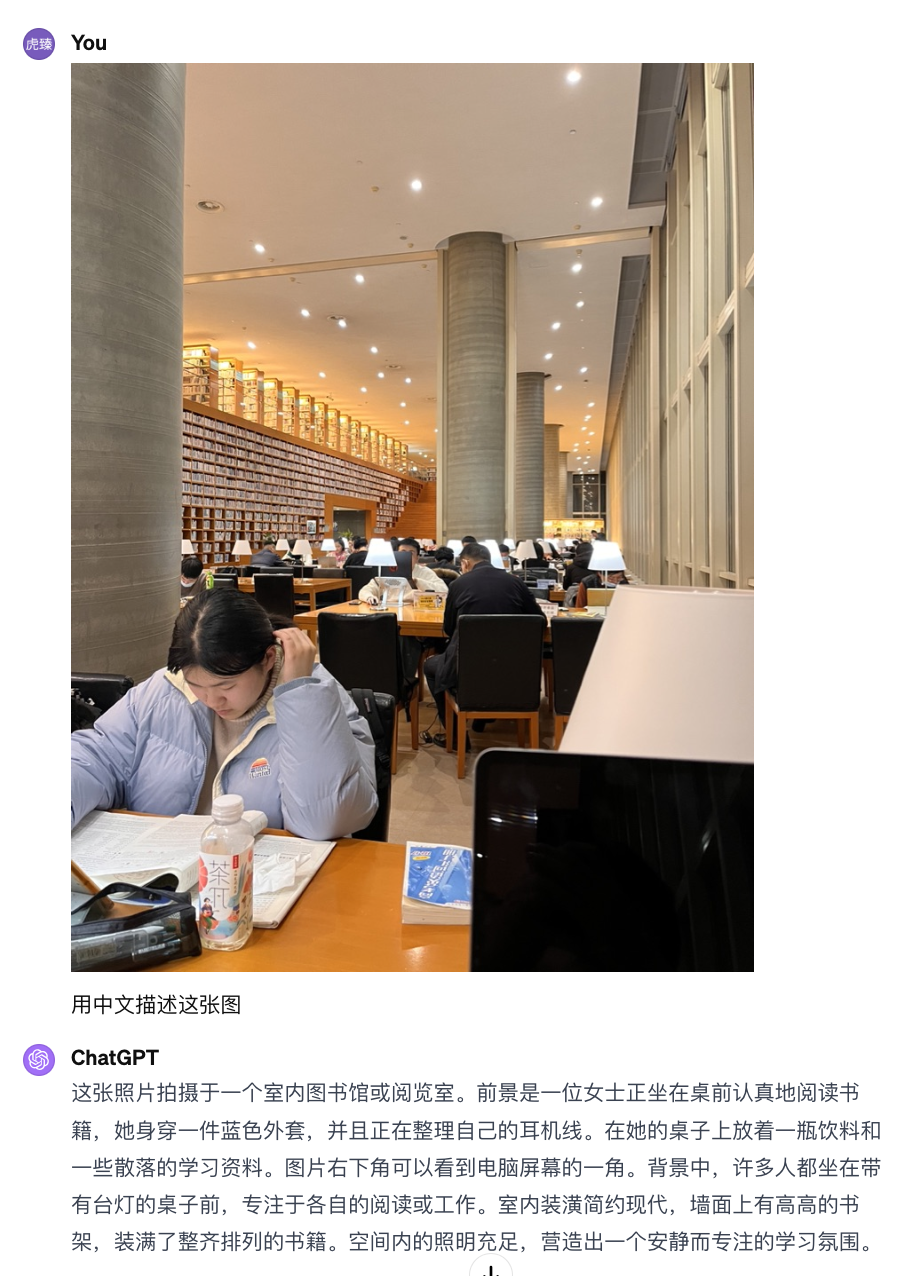
发票抽取


结论:效果较差。
Gemini Pro vs GPT4
Gemini Pro

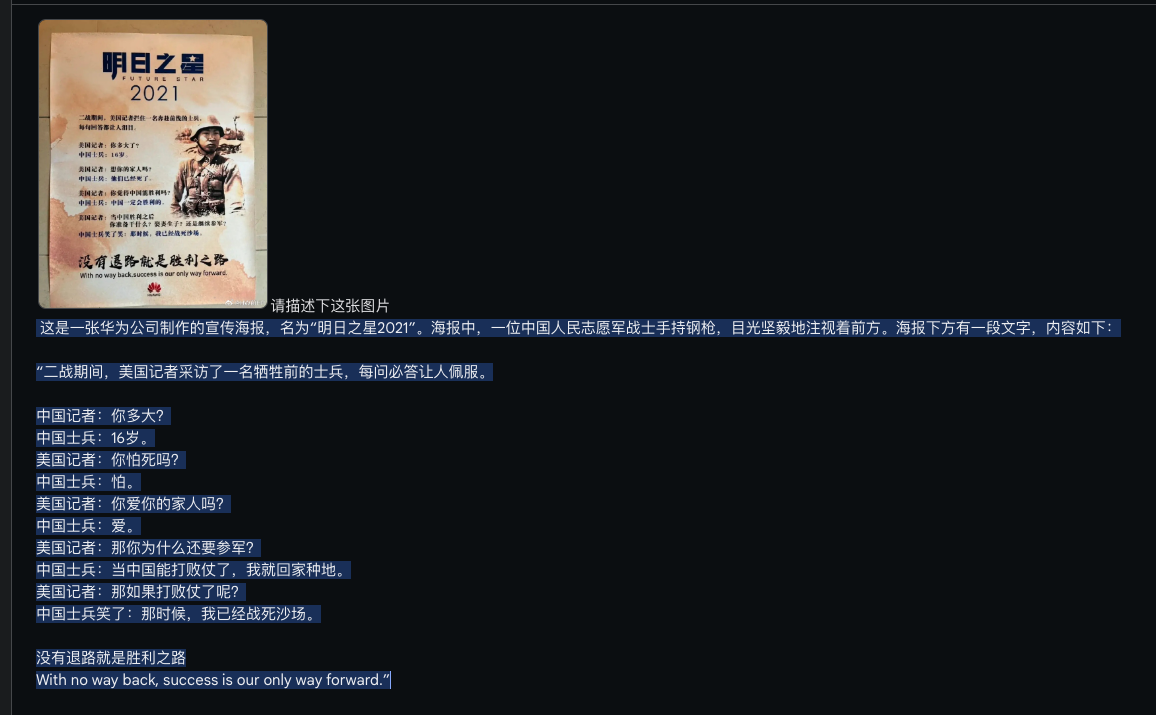




GPT4



解析结果:
1 | { |
Refs:
Google AI Studio 快速入门 | Google AI for Developers
Gemini - Google DeepMind
Hands-on with Gemini: Interacting with multimodal AI - YouTube
GPT
GPT4 Turbo
New Features:
- Context length: 12.8万个上下文tokens。(GPT4 support 8K sometimes 32K tokens)
- More control:
- 新加了 Json Model.
 其将返回json格式(这使调用api变得更容易)。
其将返回json格式(这使调用api变得更容易)。 - 调用函数更好:

- 可复制输出,传递种子参数,它使模型返回一致的输出,使你对模型行为有更高程度的控制。
- 新加了 Json Model.
- Better knowledge:
- 可以讲外部文档或数据库中的知识 带入你正在构建的任何内容。
- 拥有截止23.4月的世界知识。
- New modalities:
- DALL·E 3 , GPT-4, TTS 融合。
- 可通过api接受图像的输入,生成字幕,分类,分析。(应用:Be My Eyes 使用此 来帮助盲人)
- 文本到语音模型,能够产生逼真的自然声音,有六种预设声音可选:
- 语音可使应用程序更自然地交互,更容易访问;
- 还可 应用到 语言学习和语音助手。
- 更新了开源语音识别模型:Whisper V3
- Customization: 可定制化为公司开发GPT。
- Higher rate limits: 2x tokens per minute.
GPTs
- 为特定目的量身定制的GPT版本(如创业导师)。
- 可发布给别人使用。
- 结合了 Instructions, Expanded knowledge and Actions.
名人言论
OpenAI首席科学家Ilya Sutskever
- Nature将其评为「2023年10大科学人物」。
- 曾多次强调:只要能够非常好得预测下一个token,就能帮助人类达到AGI。
- 就像统计学一样,为了理解这些统计数据并对其进行压缩,你需要了解创建这组统计数据的世界是什么?
- OpenAI为什么放弃了机器人的方向?这是一个循序渐进的改进过程,需要建造更多机器人,收集更多数据。为了实现机器人技术的发展,必须全身心投入,并愿意解决所有相关的物理和后勤问题。这与纯粹的软件开发完全不同。只要有足够的努力和热情,机器人技术是有可能取得重大进步的,而且已经有一些公司在这方面做出了努力。
谷歌DeepMind研究副总裁Pushmeet Kohli
- 用大模型解决困扰数学家60多年的问题,谷歌DeepMind最新成果再登Nature。
- 其表示:训练数据中不会有这个方案,它之前甚至根本不为人类所知。
心得
- 掌握 可以 直接有生产力、产生价值的 技术,而非 纠结于技术细节本身,用进废退,价值最大化。